Since FSOSS my brain has been churning with many thoughts about my place in open source. According to Dave in this week's class we are all more elite than we may think and we all have potential to do great things in open source. It's hard to think that I can be in any way elite when I just failed a test in my data structures class...this is the first time I have failed anything school related and it doesn't inspire a sense of "I can take on the world". However, I know that it's just a glitch in my otherwise strong school record and so I will get beyond this.
What I've been thinking about lately is how I came to be in this program, in this open source class and how I seem to be experiencing a bit of a feeling that I am reverse engineering all the concepts that make up the open source community. My background *is* community whether it's theater, experimental films, activism, journalism, or just cultural - I have been and continue to be very active in a lot of communities. To me, a lot of the discussion about open source seems to be directed at technically sound cowboy coders who don't know how to work with others, trying to extol the virtues of a larger community and their immersion in it. I'm in the opposite lane - I know that community works, how it works and why I should be involved with it but I am constantly playing catch-up with the technical knowledge that others seem to eat and breathe.
Learning can be so erratic, it's challenging to stay focused and to not get discouraged at the fact that I often don't understand what it going on around me. In order to keep my head up I try to do something every day that is connected to school and open source learning. That can look different depending on the day. A couple of nights ago it was doing a build on a MacBook to practice for when I have my own. Yesterday it was signing up for Miro's tester mailing list and lurking on their irc channel (though that netted nothing...they are quiet folk).
One foot in front of the other, I will walk backwards and try to keep working on being a super user instead of just a user, try to be a contributor instead of a watcher, and keep telling myself that someday I will be an expert about something. That's the dream, that someday people will say "Oh you need _______, Lukas is the best person for that".
Wednesday, October 31, 2007
Friday, October 26, 2007
Long Day at FSOSS 2007
Well, it's the end of a long day. Starting out on my bike at 7:15 am and ending now, at 12:45 am (but I probably won't actually sleep until 1). I went to several talks, took lots of pictures and just wrapped up the rough draft of my FSOSS Report.
Had a great chat with Ted (:luser) about what goals to set for 0.2 and those have been posted to the project page.
That's all folks. See you tomorrow.
Had a great chat with Ted (:luser) about what goals to set for 0.2 and those have been posted to the project page.
That's all folks. See you tomorrow.
Friday, October 19, 2007
0.1 Release
Here's what we're looking at.
I built a version of ff that was checked out from mozilla's cvs. From this version I called "make buildsymbols" and created the folder 2007092823 which contained all the pdb and symbol files for that build.
For information on how to use the symbol server - check out Benjamin Smedbergs blog. Instead of pointing VStudio to the mozilla symbol server, I wanted to point to a local server of symbols.
In order to test whether these symbols worked, I set up IIS on my laptop and served up the pdbs locally to make sure that Visual Studio was able to pull them properly. After a quick detour to set up the MIME types on my server, this worked just fine.
Then I used the indexing tools that come with the microsoft.com/whdc/devtools/debugging/default.mspx Debugging for Windows package.
First - using cvsindex.cmd and pointing out the symbol path and the source path, the pdb files are then indexed with the location of the source code for that build.
Second - using srctools.exe I pulled a sample list of the source files that are contained in a pdb file
All of this is available in a zip file - PDB files and sample source list and I look forward to feedback from anyone who wants to look at the sample source list and discuss how the next step of connecting the cvs to the local pdb files might work. Also you can go to my wiki page to sign up as a contributor or to read more.
At the moment this will not work for someone who is debugging unless they have my build of FF. That's what 0.2 is all about.
I built a version of ff that was checked out from mozilla's cvs. From this version I called "make buildsymbols" and created the folder 2007092823 which contained all the pdb and symbol files for that build.
For information on how to use the symbol server - check out Benjamin Smedbergs blog. Instead of pointing VStudio to the mozilla symbol server, I wanted to point to a local server of symbols.
In order to test whether these symbols worked, I set up IIS on my laptop and served up the pdbs locally to make sure that Visual Studio was able to pull them properly. After a quick detour to set up the MIME types on my server, this worked just fine.
Then I used the indexing tools that come with the microsoft.com/whdc/devtools/debugging/default.mspx Debugging for Windows package.
First - using cvsindex.cmd and pointing out the symbol path and the source path, the pdb files are then indexed with the location of the source code for that build.
Second - using srctools.exe I pulled a sample list of the source files that are contained in a pdb file
All of this is available in a zip file - PDB files and sample source list and I look forward to feedback from anyone who wants to look at the sample source list and discuss how the next step of connecting the cvs to the local pdb files might work. Also you can go to my wiki page to sign up as a contributor or to read more.
At the moment this will not work for someone who is debugging unless they have my build of FF. That's what 0.2 is all about.
Thursday, October 18, 2007
Extensibility with Mark Finkle
Today's class was a presentation with Mark Finkle from Mozilla Corp. These are my notes.
Started off in proprietary software
Has only been with Mozilla for a year
The joy of extensions
- Primary way to get involved is through add-ons (extensions)
- Plug-ins killed the web (according to some) and are kind of discouraged
- Any app that uses the mozilla platform can be enabled to use extensions
- There's built in support in the UI, cross platform, platform APIs
Sometime people put their content in a .jar and then in the .xpi necessary for installation. Mark doesn't not advocate for this method because it can make things more confusing to new developers than need be.
He suggests keeping things as simple as you possibly can. Don't use jar files, multiple levels, keep manifests simple. Don't mimic other extensions that are often written by more experienced programmers.
Ted (:luser) has created a xul editor that can generate the skeleton for you, and if you use this then you have everything you need - just add content.
Use the pages on the MDC about the boilerplate aspects of creating extensions.
Stressed the importance of using the id of the rid firefox element to add your customized elements. Otherwise they may show up as document.getElementByID but they will not in fact appear. They will be in the ether until you merge them properly with the id. Examples are vbox id="appcontent" or statusbar id="status-bar". Not merging properly is 90% of what people get stuck on when working on the UI elements of their application and it's often that they are not using the id properly, don't have the proper id or a syntax error.
Best Slide: "Mozilla is like an Onion: It makes you cry, it smells, it has layers"
Mozilla's Tech Layers (1. XUL/JS/CSS, 2. XBL, 3. XPCOM)
Talking about layers he tells us that the top layer (the UI) is the easiest to get involved with and make changes to, but it's also the least documented and has no API. Whereas the XPCOM layer is clean and documented and has APIs so in some ways it's great to work with because it's designed to be extensible.
A demo follows about trying to dig into the code via DOM inspector.
Google searching hint - put MDC in the search criteria to help narrow the results.
Highlighting of the Code Snippets section in MDC which can really help point you in the right direction.
Thanks for coming and talking with us Mark. I look forward to working on extensions in the future.
Started off in proprietary software
Has only been with Mozilla for a year
The joy of extensions
- Primary way to get involved is through add-ons (extensions)
- Plug-ins killed the web (according to some) and are kind of discouraged
- Any app that uses the mozilla platform can be enabled to use extensions
- There's built in support in the UI, cross platform, platform APIs
Sometime people put their content in a .jar and then in the .xpi necessary for installation. Mark doesn't not advocate for this method because it can make things more confusing to new developers than need be.
He suggests keeping things as simple as you possibly can. Don't use jar files, multiple levels, keep manifests simple. Don't mimic other extensions that are often written by more experienced programmers.
Ted (:luser) has created a xul editor that can generate the skeleton for you, and if you use this then you have everything you need - just add content.
Use the pages on the MDC about the boilerplate aspects of creating extensions.
Stressed the importance of using the id of the rid firefox element to add your customized elements. Otherwise they may show up as document.getElementByID but they will not in fact appear. They will be in the ether until you merge them properly with the id. Examples are vbox id="appcontent" or statusbar id="status-bar". Not merging properly is 90% of what people get stuck on when working on the UI elements of their application and it's often that they are not using the id properly, don't have the proper id or a syntax error.
Best Slide: "Mozilla is like an Onion: It makes you cry, it smells, it has layers"
Mozilla's Tech Layers (1. XUL/JS/CSS, 2. XBL, 3. XPCOM)
Talking about layers he tells us that the top layer (the UI) is the easiest to get involved with and make changes to, but it's also the least documented and has no API. Whereas the XPCOM layer is clean and documented and has APIs so in some ways it's great to work with because it's designed to be extensible.
A demo follows about trying to dig into the code via DOM inspector.
Google searching hint - put MDC in the search criteria to help narrow the results.
Highlighting of the Code Snippets section in MDC which can really help point you in the right direction.
Thanks for coming and talking with us Mark. I look forward to working on extensions in the future.
Wednesday, October 17, 2007
Learning to Litmus
Yesterday's Club Moz meeting was quite productive as we tackled doing QA tests with Litmus.
I encourage more folks to come to Club Moz next meeting: Tuesday October 30th at 4:30 in SEQ2119 (next to ACS). Every Tuesday is a test day for Mozilla@Seneca and this is a great way of getting your feet wet in Mozilla participation with ZERO prior experience.
If you know how to browse the web you're all set.
Here's a quick how-to for those who might want to get a head start at home:
1. Set up an account with Litmus (yes, i know another mozilla account...one day this will all be better, I'm sure)
2. Pick the build version you will run tests for (it's recommended that you use a clean, new profile):

3. Enter your Build ID and your system info. An easy way to find out your build id is to type "about:" in the browser address bar:


4. This takes you to a page where you can select what kind of tests you are interested in running might be:
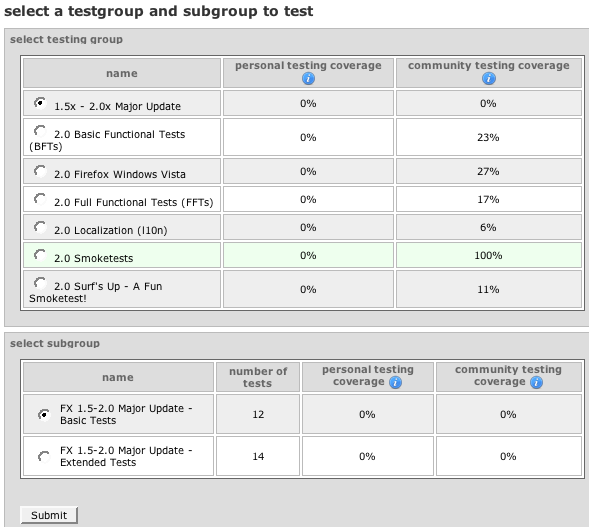
5. Make your selection and here you go - a test to run:

Many of the tests are simple things that you might do anyway.
For the competitive out there, Club Moz president Anthony Hughes is currently the 4th highest tester with 3477 tests under his belt...does anyone want to give him a run for his money?
I encourage more folks to come to Club Moz next meeting: Tuesday October 30th at 4:30 in SEQ2119 (next to ACS). Every Tuesday is a test day for Mozilla@Seneca and this is a great way of getting your feet wet in Mozilla participation with ZERO prior experience.
If you know how to browse the web you're all set.
Here's a quick how-to for those who might want to get a head start at home:
1. Set up an account with Litmus (yes, i know another mozilla account...one day this will all be better, I'm sure)
2. Pick the build version you will run tests for (it's recommended that you use a clean, new profile):
3. Enter your Build ID and your system info. An easy way to find out your build id is to type "about:" in the browser address bar:
4. This takes you to a page where you can select what kind of tests you are interested in running might be:
5. Make your selection and here you go - a test to run:
Many of the tests are simple things that you might do anyway.
For the competitive out there, Club Moz president Anthony Hughes is currently the 4th highest tester with 3477 tests under his belt...does anyone want to give him a run for his money?
Wearing grey socks makes all the difference, right?
What did I do?
Today, the indexing worked.
See the command here:
And the output.txt.
See how now it is indexing the files?! Cool.
So what did I do differently than last time?
ssindex.cmd [STATUS] : Server ini file: C:\Program Files\Debugging Tools for Windows\sdk\srcsrv\srcsrv.ini
ssindex.cmd [STATUS] : Source root : c:\ff\mozilla
ssindex.cmd [STATUS] : Symbols root : c:\ff\mozilla\objdir\dist\crashreporter-symbols\2007092823
ssindex.cmd [STATUS] : Control system : CVS
ssindex.cmd [STATUS] : CVS Root : :pserver:anonymous@cvs-mirror.mozilla.org:/cvsroot
ssindex.cmd [STATUS] : CVS program name: cvs.exe
ssindex.cmd [STATUS] : CVS Label :
ssindex.cmd [STATUS] : CVS Date : 10/09/07
ssindex.cmd [STATUS] : Old path root :
ssindex.cmd [STATUS] : New path root :
ssindex.cmd [WARN ] : Command line option "-server=cvs" is unrecognized.
--------------------------------------------------------------------------------
ssindex.cmd [STATUS] : Server ini file: C:\Program Files\Debugging Tools for Windows\sdk\srcsrv\srcsrv.ini
ssindex.cmd [STATUS] : Source root : c:\ff\mozilla
ssindex.cmd [STATUS] : Symbols root : c:\symbolServer\2007092823
ssindex.cmd [STATUS] : Control system : CVS
ssindex.cmd [STATUS] : CVS Root : :pserver:anonymous@cvs-mirror.mozilla.org:/cvsroot
ssindex.cmd [STATUS] : CVS program name: cvs.exe
ssindex.cmd [STATUS] : CVS Label :
ssindex.cmd [STATUS] : CVS Date : 10/17/2007
ssindex.cmd [STATUS] : Old path root :
ssindex.cmd [STATUS] : New path root :
So really, the only differences between this time and last time is that I pointed to the symbols on my IIS symbolServer instead of the ones that were in the crashreport-symbols. Same symbols, different location. I think that must have made more of a difference than using -debug which did not seem to do anything (and that's probably because I just re-read the documentation and it's /debug).
Now I am going to test it and run some tools on the pdb files to see what's in them.
Today, the indexing worked.
See the command here:
cvsindex -server=cvs -source=c:\ff\mozilla -symbols=c:\symbolServer\2007092823 -debug > output.txt
And the output.txt.
See how now it is indexing the files?! Cool.
So what did I do differently than last time?
Last Time:
ssindex.cmd [STATUS] : Server ini file: C:\Program Files\Debugging Tools for Windows\sdk\srcsrv\srcsrv.ini
ssindex.cmd [STATUS] : Source root : c:\ff\mozilla
ssindex.cmd [STATUS] : Symbols root : c:\ff\mozilla\objdir\dist\crashreporter-symbols\2007092823
ssindex.cmd [STATUS] : Control system : CVS
ssindex.cmd [STATUS] : CVS Root : :pserver:anonymous@cvs-mirror.mozilla.org:/cvsroot
ssindex.cmd [STATUS] : CVS program name: cvs.exe
ssindex.cmd [STATUS] : CVS Label :
ssindex.cmd [STATUS] : CVS Date : 10/09/07
ssindex.cmd [STATUS] : Old path root :
ssindex.cmd [STATUS] : New path root :
This Time:
ssindex.cmd [WARN ] : Command line option "-server=cvs" is unrecognized.
--------------------------------------------------------------------------------
ssindex.cmd [STATUS] : Server ini file: C:\Program Files\Debugging Tools for Windows\sdk\srcsrv\srcsrv.ini
ssindex.cmd [STATUS] : Source root : c:\ff\mozilla
ssindex.cmd [STATUS] : Symbols root : c:\symbolServer\2007092823
ssindex.cmd [STATUS] : Control system : CVS
ssindex.cmd [STATUS] : CVS Root : :pserver:anonymous@cvs-mirror.mozilla.org:/cvsroot
ssindex.cmd [STATUS] : CVS program name: cvs.exe
ssindex.cmd [STATUS] : CVS Label :
ssindex.cmd [STATUS] : CVS Date : 10/17/2007
ssindex.cmd [STATUS] : Old path root :
ssindex.cmd [STATUS] : New path root :
So really, the only differences between this time and last time is that I pointed to the symbols on my IIS symbolServer instead of the ones that were in the crashreport-symbols. Same symbols, different location. I think that must have made more of a difference than using -debug which did not seem to do anything (and that's probably because I just re-read the documentation and it's /debug).
Now I am going to test it and run some tools on the pdb files to see what's in them.
Monday, October 15, 2007
Going in circles
I don't know how many times I can read the 3 main sources of information about this source server business. Everytime I read them it's like being in a house of mirrors. Tonight I found a new site that refers to a source server. Once again I hear how amazing this source server is, yet no real information about how to make it happen. His final sentence - "After all, "It just works!" Why would I need to know anything more? :-)" is just poking at me as I am so in need of knowing more and can't find a single human being who knows more.
The main msdn help files state that:
So does this mean that I need to add something to the firefox build files that will do this indexing around the same time that the buildsymbols are pulled? Around the time that the build wraps up? And if yes, then what do I put there? Why is there not ONE example of someone successfully writing a source server for their project? If this source server is so amazing (and it sure sounds like it will be) then why no examples? No discussion in the msdn community forums, no blogs, nothing.
I emailed a person who sounded like they had written one for their versioning system, he wrote back and said that it actually wasn't him, it was another team member.
Is the source server really an urban legend? Has *anyone* seen it in action?
The main msdn help files state that:
Generally, binaries are source indexed during the build process after the application has been built. The information needed by source server is stored in the PDB files.
So does this mean that I need to add something to the firefox build files that will do this indexing around the same time that the buildsymbols are pulled? Around the time that the build wraps up? And if yes, then what do I put there? Why is there not ONE example of someone successfully writing a source server for their project? If this source server is so amazing (and it sure sounds like it will be) then why no examples? No discussion in the msdn community forums, no blogs, nothing.
I emailed a person who sounded like they had written one for their versioning system, he wrote back and said that it actually wasn't him, it was another team member.
Is the source server really an urban legend? Has *anyone* seen it in action?
First extension
Is done.
First attempt lead to error messages about the malformed or non-existent install.rdf file. Well, I knew it existed because I brought it into existence. So I looked around the other mozilla documents and made a replacement install.rdf - no error.
After this point though, I hit a wall because I could install the extension and yet the tabs weren't being added to the side. So I checked the Error Console, no errors related to the addtabbeside extension. After entering some dump() messages in the addtabbeside.js file I try again, starting ff with -console. Nothing to go on.
Anyway, a while later I found mullin on IRC and we troubleshooted it. He knew that the xml spacing is all messed up with you copy and paste from the wiki - I started from scratch paying closer attention to the indentation and voila!
So what I have learned from this is to be careful of indentation when I copy and paste. I look forward to my next extension, when I can really get deeper into modifying the browser, like menu items and whatnot.
First attempt lead to error messages about the malformed or non-existent install.rdf file. Well, I knew it existed because I brought it into existence. So I looked around the other mozilla documents and made a replacement install.rdf - no error.
After this point though, I hit a wall because I could install the extension and yet the tabs weren't being added to the side. So I checked the Error Console, no errors related to the addtabbeside extension. After entering some dump() messages in the addtabbeside.js file I try again, starting ff with -console. Nothing to go on.
Anyway, a while later I found mullin on IRC and we troubleshooted it. He knew that the xml spacing is all messed up with you copy and paste from the wiki - I started from scratch paying closer attention to the indentation and voila!
So what I have learned from this is to be careful of indentation when I copy and paste. I look forward to my next extension, when I can really get deeper into modifying the browser, like menu items and whatnot.
Oh Bugzilla
Well I'm a little late in reporting on my experience of watching someone on Bugzilla. This is partly because I didn't read the "to-dos" closely enough and then it was because it took a few hours to find out how to watch someone. Well, asking on IRC, I was informed that you go to your user settings. What?! That is so strange. I wish that Bugzilla had a better interface where you could search by user, email, etc. Something to connect you to the people more. The current interface assumes you already know how to use everything.
Anyway, I put Ted (:luser) on my watch list because he's my main contact for the project I'm working on.
Mullin already said it, but I will say it again - the flood of emails made no sense, I had no way of knowing who commented from the subject line of the email, and basically it took less than one day before I pretty much stopped paying attention to anything from bugzilla-daemon@mozilla.org.
I am impressed with anyone who uses this system and gets something out of it.
Armen says there's no way bugzilla can change because it's too big - is that really true?
Anyway, I put Ted (:luser) on my watch list because he's my main contact for the project I'm working on.
Mullin already said it, but I will say it again - the flood of emails made no sense, I had no way of knowing who commented from the subject line of the email, and basically it took less than one day before I pretty much stopped paying attention to anything from bugzilla-daemon@mozilla.org.
I am impressed with anyone who uses this system and gets something out of it.
Armen says there's no way bugzilla can change because it's too big - is that really true?
Sunday, October 14, 2007
Ontario Linux Fest 2007
My Experience at Ontario Linux Fest 2007 - At the Toronto Congress Center.
Woke up at 6 am to get the dog walked and eat some breakfast before heading out to get Cesar. Thanks Cesar for being awake and ready to go!
We had to go up to Seneca first and grab the display material from Mary, who was also awake and on time. Perfect so far. Then we headed up to the airport vicinity where the google map had said the center was and I promptly got us a little lost. After checking at the gas station for direction, we were set straight and arrived on time to the conference center where we signed in, got a bag 'o shwag and found our table.


Once we were set up, I went to the "Women in Open Source" talk that Angela Byron was giving at 9:30. This was an excellent presentation and I was really excited to meet her in person and to talk briefly about her Summer of Code experience. I have been stalking that site for 2 years now and was never sure if it was something I could do or if only elite hackers applied. Meeting a real person who has done it and can speak to how it worked for her was inspiring. She works with Lullabot and thus, Drupal. After her talk I went to a "Hands on Demo" of Joomla and got to see how the other half lives. Joomla is exciting to me and I look forward to having a little bit of time to test out setting up a simple site with it.
Cesar had dutifully staffed the booth for a couple of hours so I went and took over so he could wander around and go to OpenMoko after lunch. At one point though, we plastered all the tables in both session halls with FSOSS flyers so as to get maximum awareness.
Talking to people about FSOSS was great - a lot of folks already knew about it and were coming. I spent a little time talking with Dru Lavigne and learning about FreeBSD. I even got a few install disks so maybe I'll be testing it out on a virtual machine soon. A few good networking opportunities presented themselves. I met the guy who does all the Linux on mainframes stuff for IBM and he gave me his card to contact him about IBM online learning.
In the afternoon I listened to the story of a LUG partnering up with the United Way up around Owen Sound and fixing up computers for families in need. I hear that we're doing some similar stuff at Seneca, so I'm going to be looking into how I could help with that project. What I like about this kind of project is that it can be anonymous - so that people in need don't have to feel like they are getting handouts. Also, this is a great opportunity to work on making Linux useable to people with ZERO technical skills. That's something I think really needs to keep being improved if there is going to be wider adoption. It also interests me because I need to become more comfortable with installing and configuring Linux so I can be an evangelist.
All in all, a great time was had and I came away with lots of new knowledge and curiousity about Linux and the community surrounding it plus, some new friendships in the making. I could get used to this conference lifestyle.
As a parting note:

did that penguin just move?
Woke up at 6 am to get the dog walked and eat some breakfast before heading out to get Cesar. Thanks Cesar for being awake and ready to go!
We had to go up to Seneca first and grab the display material from Mary, who was also awake and on time. Perfect so far. Then we headed up to the airport vicinity where the google map had said the center was and I promptly got us a little lost. After checking at the gas station for direction, we were set straight and arrived on time to the conference center where we signed in, got a bag 'o shwag and found our table.
Once we were set up, I went to the "Women in Open Source" talk that Angela Byron was giving at 9:30. This was an excellent presentation and I was really excited to meet her in person and to talk briefly about her Summer of Code experience. I have been stalking that site for 2 years now and was never sure if it was something I could do or if only elite hackers applied. Meeting a real person who has done it and can speak to how it worked for her was inspiring. She works with Lullabot and thus, Drupal. After her talk I went to a "Hands on Demo" of Joomla and got to see how the other half lives. Joomla is exciting to me and I look forward to having a little bit of time to test out setting up a simple site with it.
Cesar had dutifully staffed the booth for a couple of hours so I went and took over so he could wander around and go to OpenMoko after lunch. At one point though, we plastered all the tables in both session halls with FSOSS flyers so as to get maximum awareness.
Talking to people about FSOSS was great - a lot of folks already knew about it and were coming. I spent a little time talking with Dru Lavigne and learning about FreeBSD. I even got a few install disks so maybe I'll be testing it out on a virtual machine soon. A few good networking opportunities presented themselves. I met the guy who does all the Linux on mainframes stuff for IBM and he gave me his card to contact him about IBM online learning.
In the afternoon I listened to the story of a LUG partnering up with the United Way up around Owen Sound and fixing up computers for families in need. I hear that we're doing some similar stuff at Seneca, so I'm going to be looking into how I could help with that project. What I like about this kind of project is that it can be anonymous - so that people in need don't have to feel like they are getting handouts. Also, this is a great opportunity to work on making Linux useable to people with ZERO technical skills. That's something I think really needs to keep being improved if there is going to be wider adoption. It also interests me because I need to become more comfortable with installing and configuring Linux so I can be an evangelist.
All in all, a great time was had and I came away with lots of new knowledge and curiousity about Linux and the community surrounding it plus, some new friendships in the making. I could get used to this conference lifestyle.
As a parting note:
did that penguin just move?
Friday, October 12, 2007
I will do anything
To get the information that I need to make this Source Server work.
So in the srcsrv.doc file that comes with the debugging package it says:
So I did.
Here's the response I just got:
Well that's interesting because in my sdk I have a CVS.pm and a cvsindex.cmd which is what you need to make this stuff work with CVS. So does Pat know that? Is there a better version on the way?
What I don't understand right this second is two things:
1. How does the actual indexing of PDB files happen? According to my main source of information (becoming as dog-eared as a web page can get):
Does this mean that I should be calling SSINDEX.CMD and not CVSINDEX.CMD? Does this look through all folders in the named path? When I ran it yesterday I did several variations but to no apparent success.
and...I've forgotten the second thing. It will come to me.
So in the srcsrv.doc file that comes with the debugging package it says:
Anyone interested in using Source Server with CVS should send email to windbgfb@microsoft.com.
So I did.
Here's the response I just got:
Good things come to those that wait – and you will not have to wait long. The next debugger release will have cvs source indexing scripts in it. You will probably need to tweak them since cvs installations seem to differ greatly and I was unable to come up with something that was truly general-purpose.
So watch our web site for the release. It will be out soon.
.pat styles
Well that's interesting because in my sdk I have a CVS.pm and a cvsindex.cmd which is what you need to make this stuff work with CVS. So does Pat know that? Is there a better version on the way?
What I don't understand right this second is two things:
1. How does the actual indexing of PDB files happen? According to my main source of information (becoming as dog-eared as a web page can get):
When you run SSINDEX.CMD, after it validates parameters it asks the version control system for the list of all source files (and their version numbers) in the target project and below. PDB files are then searched for recursively. For each PDB file found, the Perl code calls SRCTOOL.EXE to extract the list of source files. The code looks through the source files in the PDB file and sees if they match any of the files stored earlier from the version control search: if a match is found, the code saves that file info.
Does this mean that I should be calling SSINDEX.CMD and not CVSINDEX.CMD? Does this look through all folders in the named path? When I ran it yesterday I did several variations but to no apparent success.
and...I've forgotten the second thing. It will come to me.
Thursday, October 11, 2007
My first patch, a true story
Well. I am jazzed up while I sit in BTB right now because I MADE A PATCH!
Yessir. The lab for today's class asked us to try and modify our browsers so that opening a new tab makes it appear to the right of the current tab, instead of the way it currently opens the new tab at the far right end of all tabs.
We all jumped on to MXR and ... it froze. So for a bit, I stared at the screen and wondered - "How hard is this going to be?".
Well, not too bad actually. I searched for "New Tab" and found /browser/base/content/tabbrowser.xml which has a comment:
Looks like I'm in the right place.
Turns out tabbrowser.xml is the best place to go because that's where my changes will be made and it also happens to be where all the methods regarding tabs are located.
Now I'm staring at some javascript. Immediate guilt sets in for not being more competent in this language. When did we take javascript? Back in third term. It's now buried beneath a tiny bit of perl, a pinch of php and attempts at ruby.
loadOneTab() is called when a new tab is added, loadOneTab() calls on addTab(). These are all in the same file. I'm focusing on addTab(). This is my target for adding some lines.
addTab() creates a tab object with the variable name t and then appendChild(t) to mTabContainer. Let's look at mTabContainer...
What do you know - it has a method called moveTabTo(). Cool, that's what I want to do. I want to moveTabTo() the index next to the one that's calling the addTab().
See tabPatch to get the rest of the story I've got to go do a victory lap.
Yessir. The lab for today's class asked us to try and modify our browsers so that opening a new tab makes it appear to the right of the current tab, instead of the way it currently opens the new tab at the far right end of all tabs.
We all jumped on to MXR and ... it froze. So for a bit, I stared at the screen and wondered - "How hard is this going to be?".
Well, not too bad actually. I searched for "New Tab" and found /browser/base/content/tabbrowser.xml which has a comment:
// We're adding a new tab here.
Looks like I'm in the right place.
Turns out tabbrowser.xml is the best place to go because that's where my changes will be made and it also happens to be where all the methods regarding tabs are located.
Now I'm staring at some javascript. Immediate guilt sets in for not being more competent in this language. When did we take javascript? Back in third term. It's now buried beneath a tiny bit of perl, a pinch of php and attempts at ruby.
loadOneTab() is called when a new tab is added, loadOneTab() calls on addTab(). These are all in the same file. I'm focusing on addTab(). This is my target for adding some lines.
addTab() creates a tab object with the variable name t and then appendChild(t) to mTabContainer. Let's look at mTabContainer...
What do you know - it has a method called moveTabTo(). Cool, that's what I want to do. I want to moveTabTo() the index next to the one that's calling the addTab().
See tabPatch to get the rest of the story I've got to go do a victory lap.
Tuesday, October 9, 2007
Source Indexing - setting up for CVS
Included with WinDBG's debugging tools is an sdk that has some scripts to use for making a Source Server.
From what I have gathered so far, I needed to configure the srcsrv.ini file to point to my CVS repository - check, i pointed it to MYSERVER=:pserver:anonymous@cvs-mirror.mozilla.org:/cvsroot
Then I ran ssindex.cmd –server=cvs –source=c:\source –symbols=c:\outputdir with the appropriate locations.
First error:
Okay, so I realized that I should have been calling cvsindex.cmd NOT ssindex.cmd. Re-do the call...
Second error:
Gotta love that "can't continue", how dramatic. I remembered reading about the Label and Date setting when looking at the documentation for cvsindex.cmd -?? and thanks to Dave for noticing that it says "OR" not "AND" - so I set the CVS_DATE to today's date and go for third.
Third results:
And it did take time...but after all was said and done - nothing seems to be indexed. Minor success anyway, I learned how to run the indexing command.
Back to the drawing board.
Thanks to everyone on #seneca who reassured me that I wouldn't break the CVS repository by messing around with this.
From what I have gathered so far, I needed to configure the srcsrv.ini file to point to my CVS repository - check, i pointed it to MYSERVER=:pserver:anonymous@cvs-mirror.mozilla.org:/cvsroot
Then I ran ssindex.cmd –server=cvs –source=c:\source –symbols=c:\outputdir with the appropriate locations.
First error:
ssindex.cmd [ERROR ] : A source control system must be specified using either the
"-SYSTEM=" option or by defining SRCSRV_SYSTEM in your environment.Okay, so I realized that I should have been calling cvsindex.cmd NOT ssindex.cmd. Re-do the call...
Second error:
ssindex.cmd [ERROR ] CVS: CVS_LABEL or CVS_DATE not defined. Can't continue.Gotta love that "can't continue", how dramatic. I remembered reading about the Label and Date setting when looking at the documentation for cvsindex.cmd -?? and thanks to Dave for noticing that it says "OR" not "AND" - so I set the CVS_DATE to today's date and go for third.
Third results:
--------------------------------------------------------------------------------
ssindex.cmd [STATUS] : Server ini file: C:\Program Files\Debugging Tools for Windows\sdk\srcsrv\srcsrv.ini
ssindex.cmd [STATUS] : Source root : c:\ff\mozilla
ssindex.cmd [STATUS] : Symbols root : c:\ff\mozilla\objdir\dist\crashreporter-symbols\2007092823
ssindex.cmd [STATUS] : Control system : CVS
ssindex.cmd [STATUS] : CVS Root : :pserver:anonymous@cvs-mirror.mozilla.org:/cvsroot
ssindex.cmd [STATUS] : CVS program name: cvs.exe
ssindex.cmd [STATUS] : CVS Label :
ssindex.cmd [STATUS] : CVS Date : 10/09/07
ssindex.cmd [STATUS] : Old path root :
ssindex.cmd [STATUS] : New path root :
--------------------------------------------------------------------------------
ssindex.cmd [STATUS] : Running... this will take some time... And it did take time...but after all was said and done - nothing seems to be indexed. Minor success anyway, I learned how to run the indexing command.
Back to the drawing board.
Thanks to everyone on #seneca who reassured me that I wouldn't break the CVS repository by messing around with this.
When doubt creeps in...
Oh boy, what have I taken on?
Going deeper and deeper into any documentation I can find about how one goes about source indexing. I have no idea what I've signed up for.
In my C:\Program Files\Debugging Tools for Windows\sdk\srcsrv directory there is an excellent source server document that walks through the steps and for the moment all I know is that I'll be needing Perl.
So I'm downloading ActivePerl as I write this and hopefully once it's installed I can chip away at setting up some indexing scripts.
Going deeper and deeper into any documentation I can find about how one goes about source indexing. I have no idea what I've signed up for.
In my C:\Program Files\Debugging Tools for Windows\sdk\srcsrv directory there is an excellent source server document that walks through the steps and for the moment all I know is that I'll be needing Perl.
So I'm downloading ActivePerl as I write this and hopefully once it's installed I can chip away at setting up some indexing scripts.
Monday, October 1, 2007
IIS is serving up PDB files locally
Well, thanks to Peter McIntyre (Resident Windows Genius) at Seneca College, I have now managed to set up my local symbol server.
Peter actually sent me a link to information about configuring IIS 6.0 but it turned out I had 5.1 - no problem he had given me enough so that a quick Google was all it took to find this script to which I merely added ".pdb", "application/octet-stream" and voila - my MIME map is updated. Now my localhost symbol server can serve up .pdb files without a hitch.
Started up Minefield, attached to VStudio and the symbols loaded up as smooth as can be.
Small success leads to much dancing around with the hound dog.
In other news, finished part 1 of the IBM "Master the Mainframe" contest (if anyone wants to do it, register using Peter as your Faculty person) and am slowly working through part 2...with breaks for reading up on bugs. I still find the whole bugzilla environment quite daunting, it's like that feeling that everyone else knows what they're doing except me. This is me, peering around the corner and listening in...
Peter actually sent me a link to information about configuring IIS 6.0 but it turned out I had 5.1 - no problem he had given me enough so that a quick Google was all it took to find this script to which I merely added ".pdb", "application/octet-stream" and voila - my MIME map is updated. Now my localhost symbol server can serve up .pdb files without a hitch.
Started up Minefield, attached to VStudio and the symbols loaded up as smooth as can be.
Small success leads to much dancing around with the hound dog.
In other news, finished part 1 of the IBM "Master the Mainframe" contest (if anyone wants to do it, register using Peter as your Faculty person) and am slowly working through part 2...with breaks for reading up on bugs. I still find the whole bugzilla environment quite daunting, it's like that feeling that everyone else knows what they're doing except me. This is me, peering around the corner and listening in...
Subscribe to:
Posts (Atom)